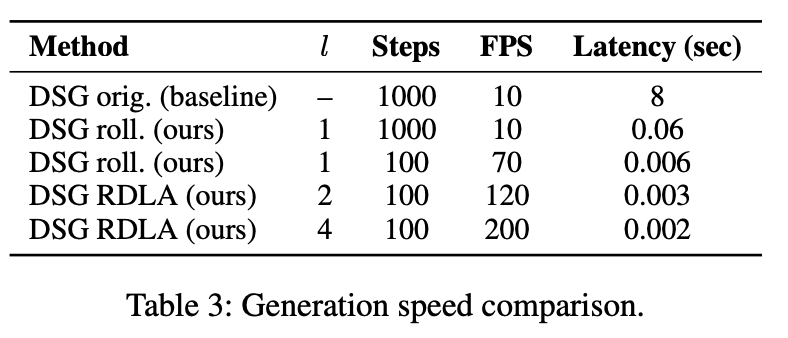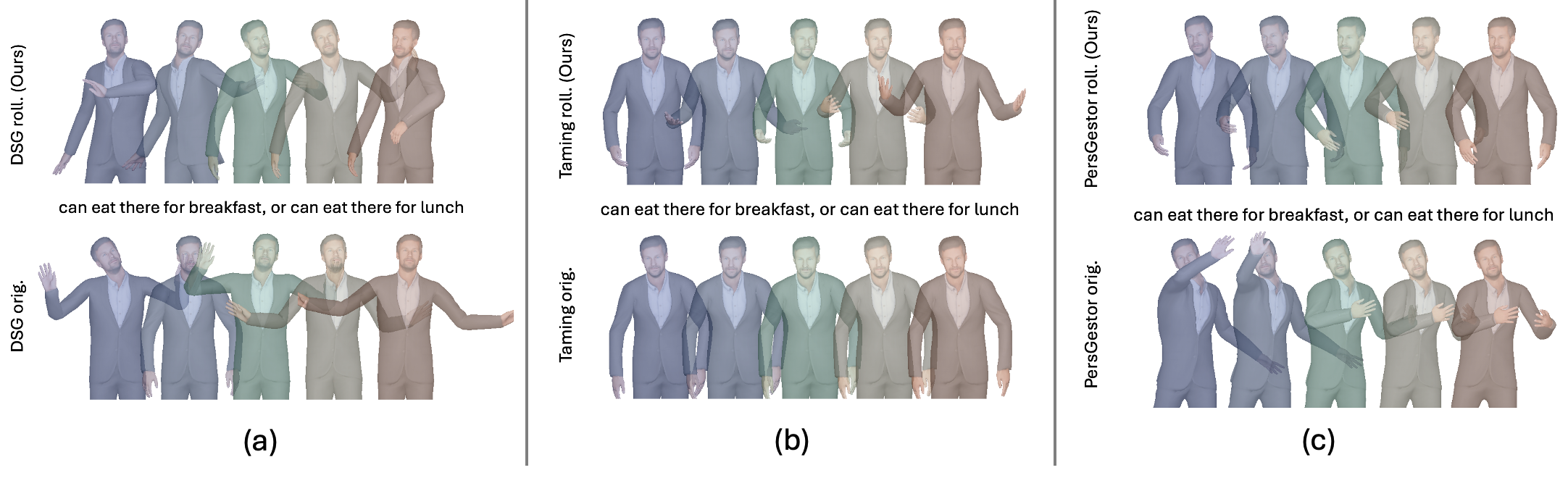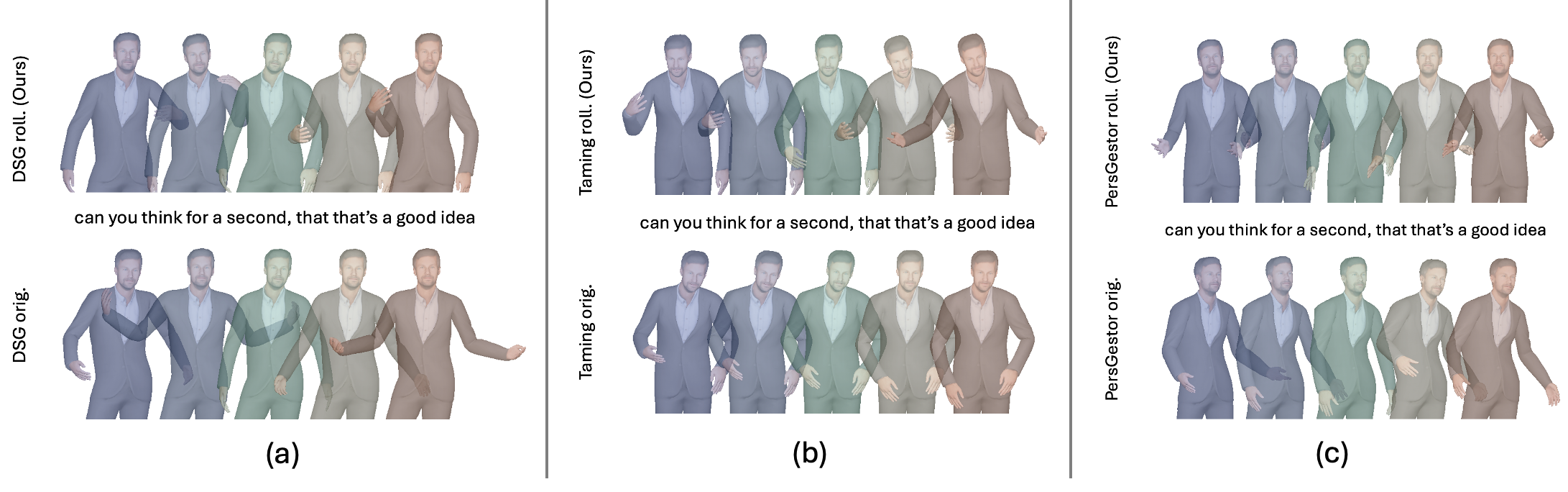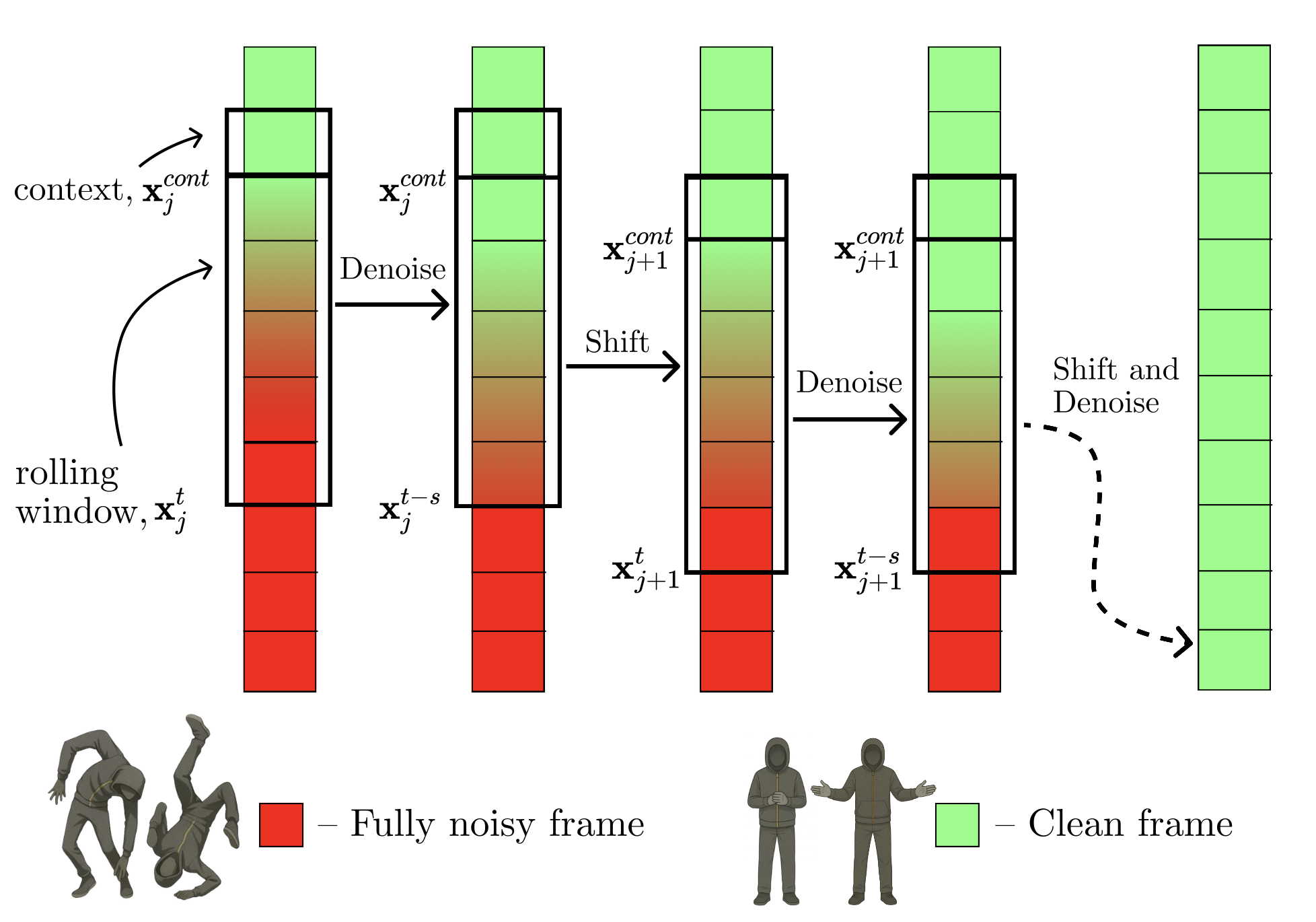
Framework
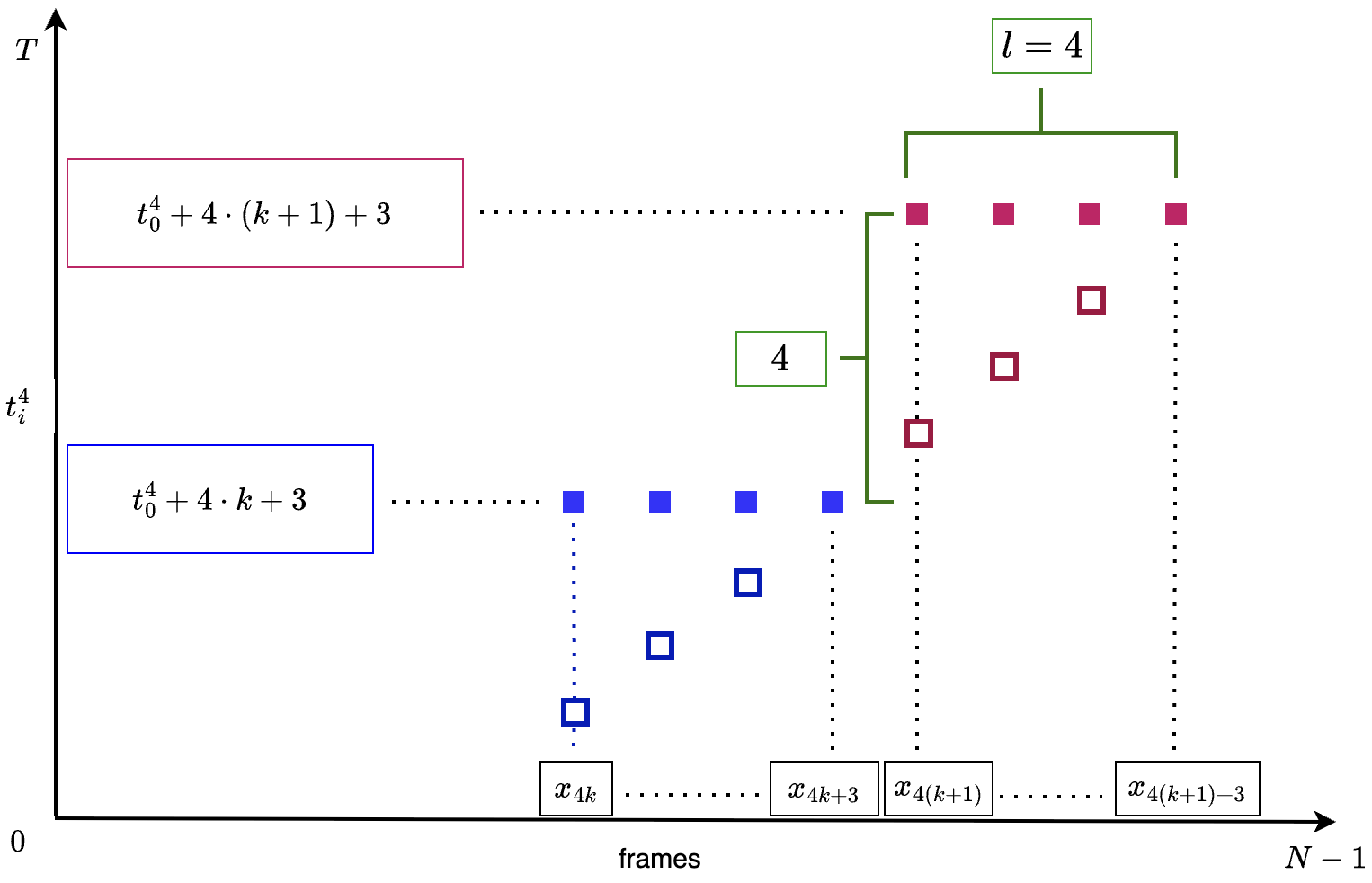
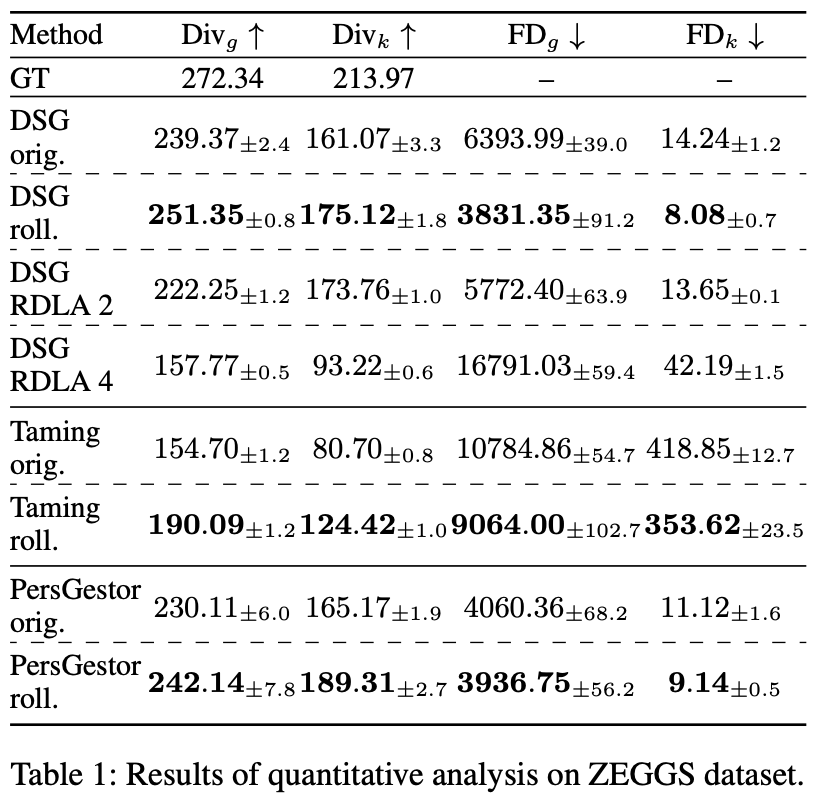
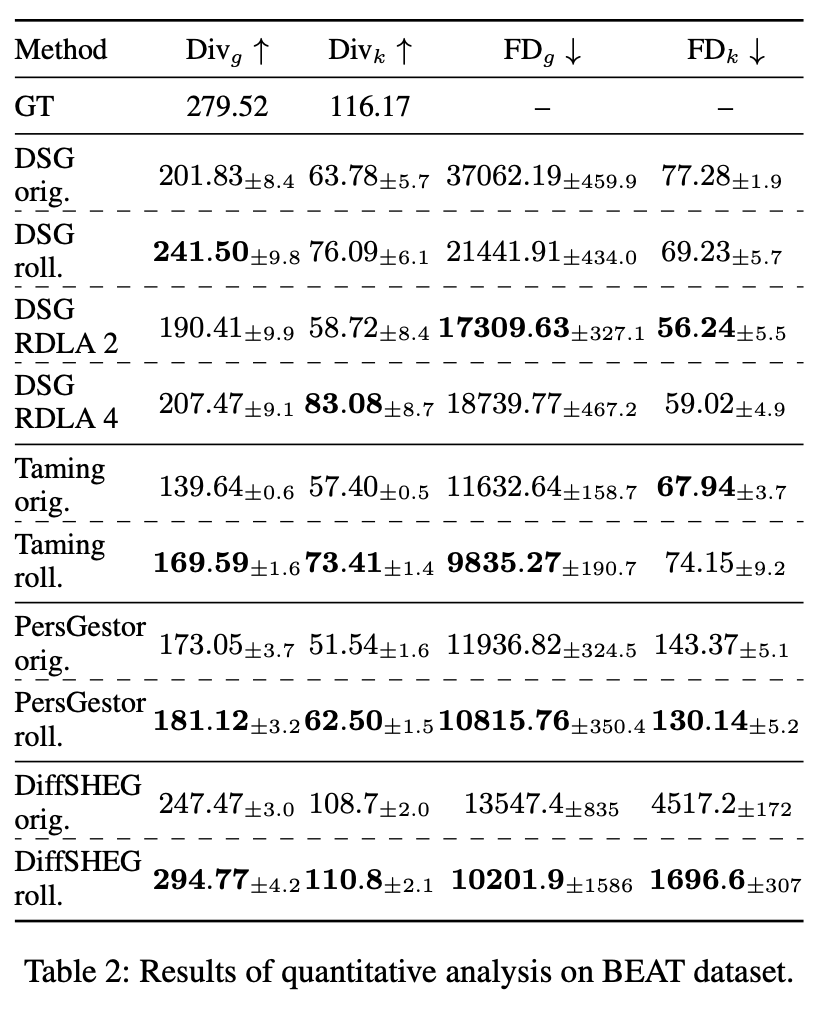
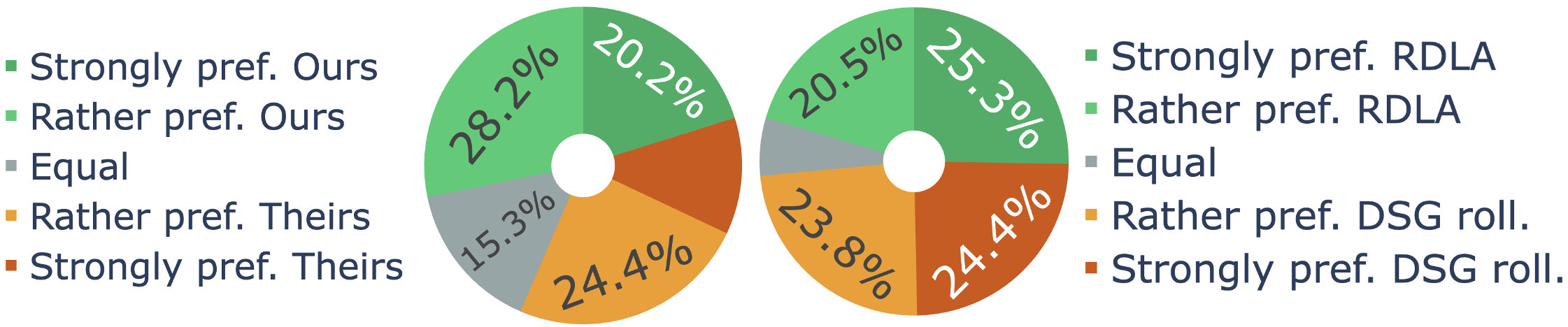
In our work, we adapt rolling diffusion models for co-speech gesture generation, introducing a novel framework that transforms any diffusion-based architecture into an autoregressive streaming model. Our approach enables seamless and continuous gesture generation of arbitrary length by modifying the model architecture and integrating a structured noise scheduling mechanism, which, combined with the rolling denoising process, ensures smooth temporal transitions and prevents abrupt motion discontinuities. The model generates a new clean frame in each s-step and shifts the generation window forward to include the new frame at the end.